Stable diffusion超详细系列教程2-轻松搞定各种安装和插件问题
上篇比较硬核的自主安装教程,果然看的人就少了很多,看样子劝退了一部分人。
不少同学私聊我说有一键安装包,我当然也知道。还有云端部署,其实我去年就写过教程。之所以写硬核一点的自主安装教程,就是希望你能从自主安装过程中了解它的基本运行原理,并享受研究的快乐!
为了研究 Win 和 Mac 双端安装过程,我自己其实也折腾了一天时间,安装过程极不顺利,走了不少弯路,但也因此学到很多除了安装外的很多知识,实操后对原理配置掌握得更熟练了,这可能就是走复杂之路收获的意外之喜。
这其中有几点经验想和你分享:
1)大部分报错,都是因为网络问题。科学上网很重要,而如果想让你的终端强制走你的科学上网通道,可以在科学上网工具中找到一个选项叫“复制终端代理命令”,复制代码后贴进终端,回车即可。
2)如果还有失败报错,先尝试自己搜索,把错误代码直接复制到Google,重点看github和reddit这2个网站中的答案,我很多问题都是在这里面得到解决的。
3)保持耐心,其实我的安装过程也并不顺利。但为了写教程,必须研究明白,当有了目标后逼着自己解决了问题,最终都安装成功了。我遇到的所有疑难杂症,最后都是我自己解决的,没有求助过任何一个人。
如果你在安装过程中发现不顺利,别放弃。教程方法都是我亲测的,也毫无保留地分享了出来,只要方法没错,搞定只是时间问题,坚信你自己一定可以。所以,只要你有足够的耐心,不但最终你一定可以学会,而且相信你会学到更多。
但如果你实在觉得麻烦,被硬核安装方法折腾到快要放弃,就想要一键安装的操作,那么今天的文章会帮你彻底解决它。
今天的更新算是上一篇《AI绘画新篇章,stable diffusion系列教程1》的补充,我会分享更简单的整合包安装,以及考虑到有些朋友的电脑硬件可能不给力,也分享一种最简单的云端安装方式。最后还会分享好用的绘画插件以及AI绘画资源包,值得收藏和分享。
1.一键安装stable diffusion整合包
对于使用windows系统的朋友来说,推荐使用B站大佬秋葉aaaki的整合包。
整合包安装特别简单,也没什么太多值得写的东西,大家自行去B站看这个教程:
或者在文末用我整合在一起的AI绘画资料包也可以,我把整合包、插件包和模型都放在一起了,方便大家下载安装。
2.云端安装
这个过程,网速快的话,不到3分钟安装完。如果你的电脑不够给力,可以用这种云端方式。
1)利用colab进行启动文件安装
先进到colab,在电脑(我测试过在手机上也可以跑这套流程,但不建议,界面UI会非常糟糕)上打开这个链接:
https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb#scrollTo=Y9EBc437WDOs

colab打开后的安装界面
2)按序号逐个点击左边的图标运行代码
每个部分执行完后会显示done
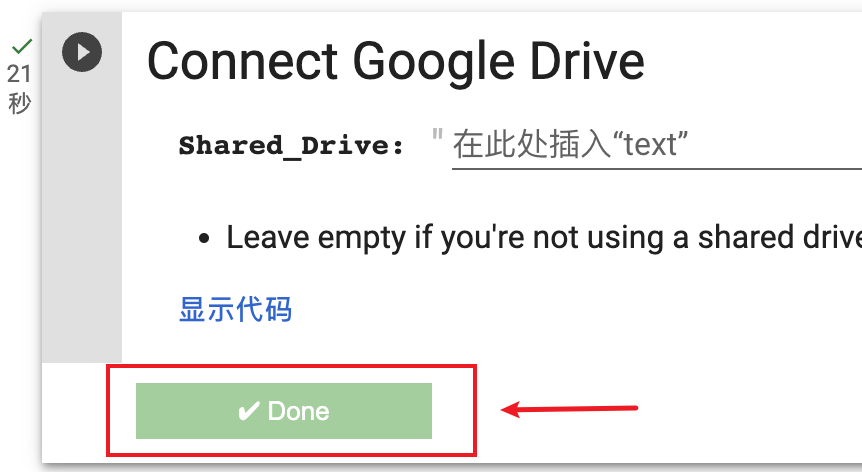
一定要按顺序来操作

当最后一步出现这个链接时,代表安装完成。
点这个链接就能看到stable diffusion操作界面了。
跟本地几乎是一样的,只不过这次用上了谷歌云盘作为放stable diffusion主程序和模型的地方。
3)再次启动
如果你已经按我上面说的安装过,下次再启动时,只需要启动最后一个运行图标即可用上stable diffusion,还是很方便的。
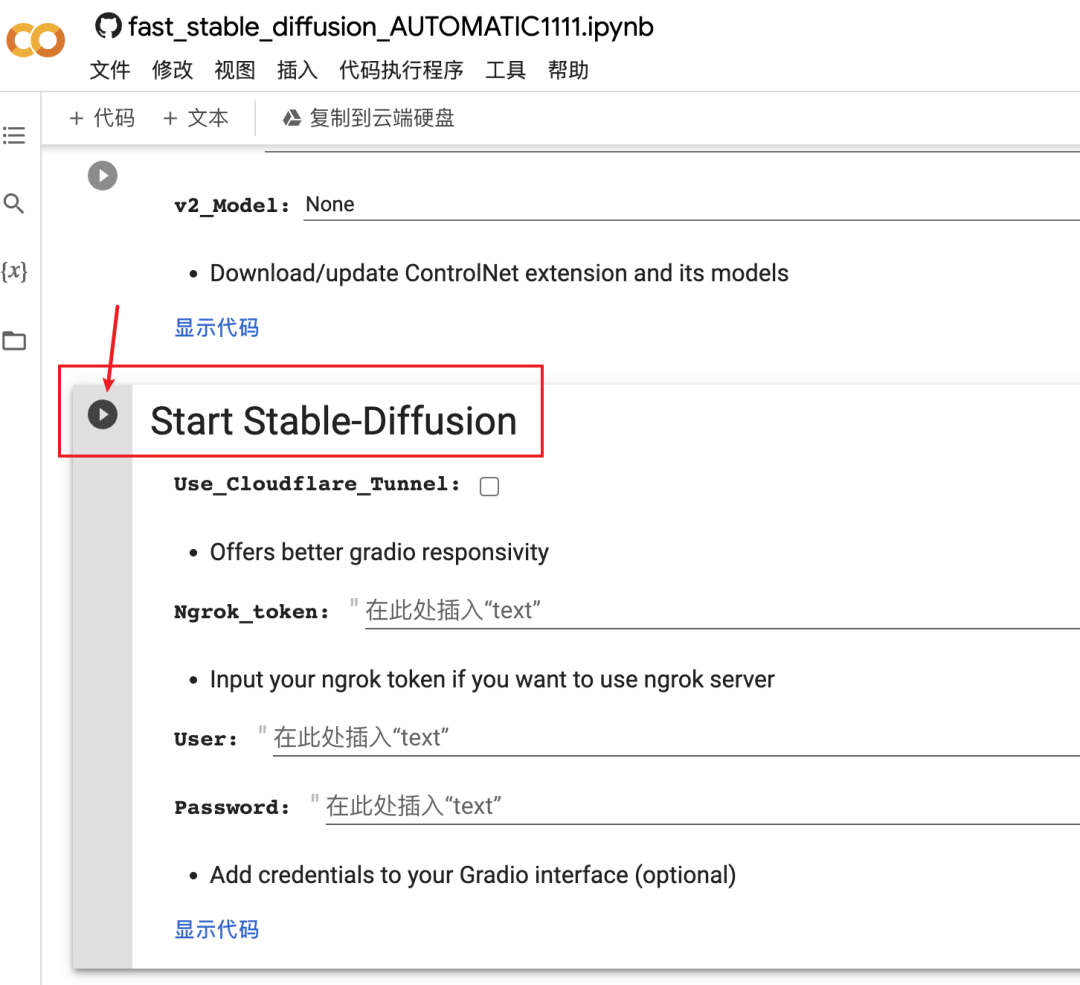
提醒一点:在完成工作后记得关闭 Colab 标签页,因为它的内存是动态变化的,如果你开启服务后不关页面,也会算你在使用额度,可能会出现提醒你额度不足。

3.插件安装
插件是安装在extensions目录中,安装方法也很简单。
大部分的插件都在Extensions—available中可以找到,点下Load from就可以看到,然后选择你想要的插件点Install安装就行。(这里提醒下,有时候通过这种方式不一定能安装成功,可以多尝试几次)
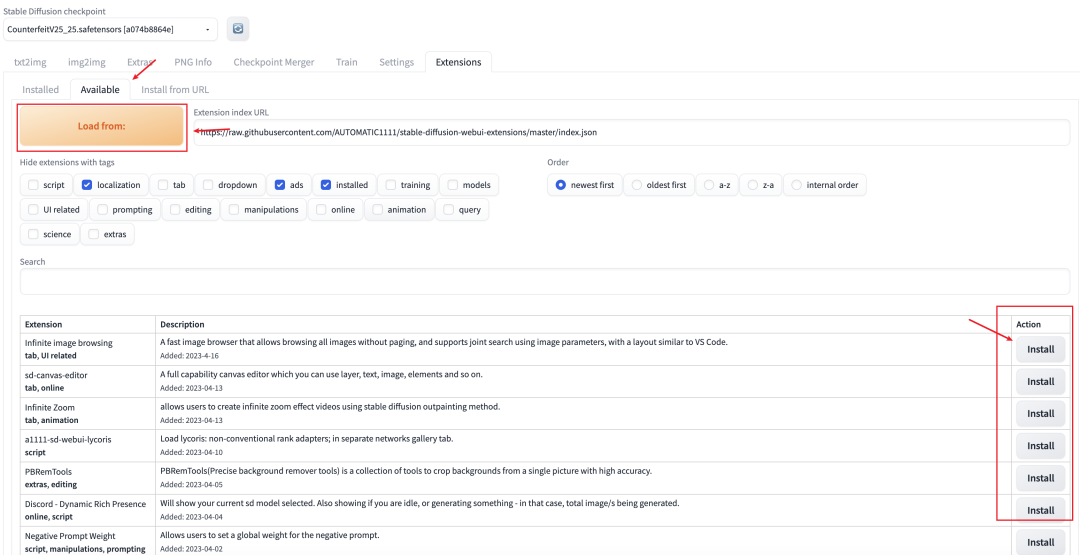
或者可以用我给的插件安装包,把插件复制到本地stable diffusion的扩展文件夹中,这样安装是最不容易出错的。
安装好了之后,一定要重启UI界面才能看到插件。(提醒下,这里的重启UI界面是需要点击”重启按钮”,刷新页面是没用的)
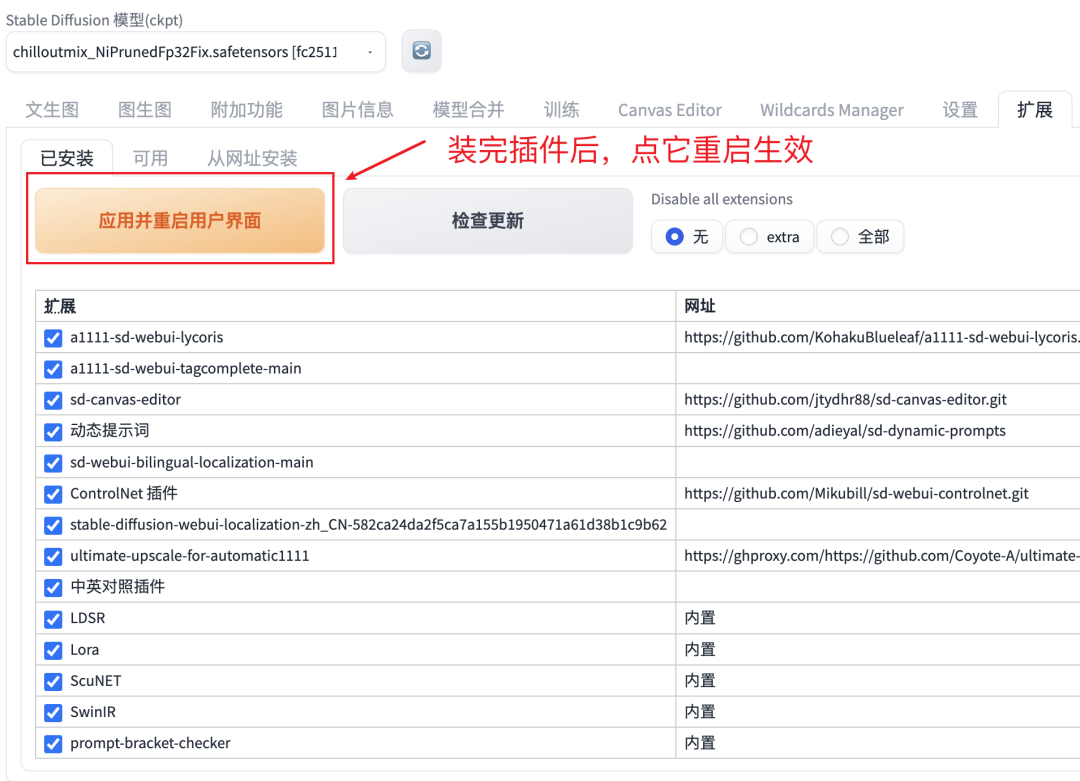
点这里重启UI
这里给一个小技巧:有时候需要经常打开安装目录放自己的模型和插件,在终端里进行操作打开是非常方便的。先用上下键找到自己之前的命令记录:cd stable-diffusion-webui,回车进到自己的安装目录,然后输入“open .” 命令,直接回车打开文件目录。
这里我也给大家推荐几个最常用的基础插件
1)中英对照tag自动补齐
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
这个插件能汉化UI界面、Tag自动补全、提示词prompt翻译等功能,解决英文不好的问题,有效减少用翻译软件的时间,不过测试发现词库并不全,有些可能还会用到翻译软件。
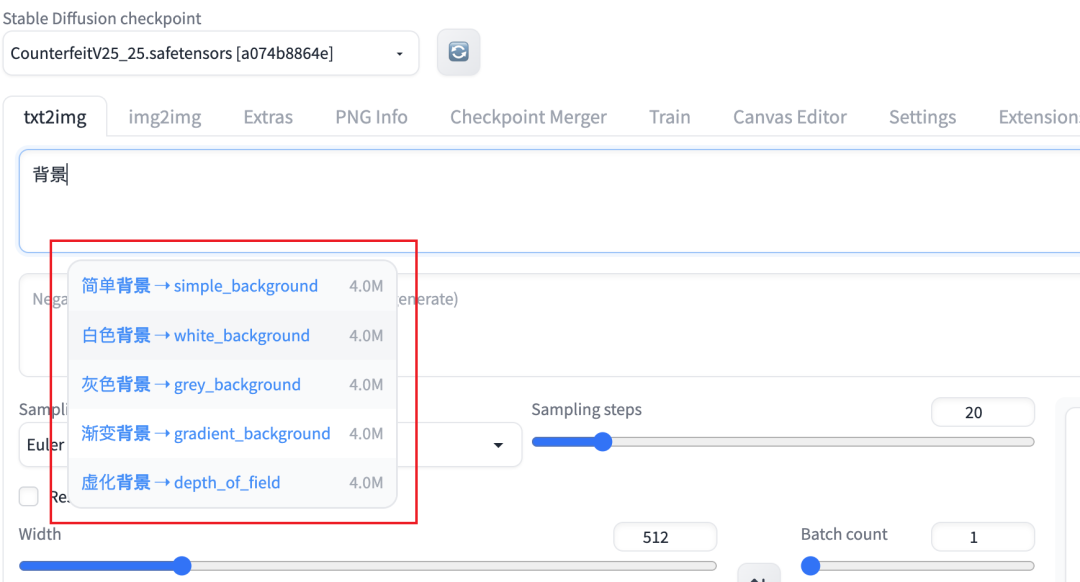
使用效果如上,还是很实用的
想要安装这个插件,需要先装一个前置插件,叫“a1111-sd-webui-tagcomplete-main” 安装方法和前面一样,可以搜“booru tag autocompletion”点击安装

也可以在github上下载插件压缩包,解压后放到本地文件夹的目录里。推荐用第二种方式安装,更顺利。安装包资料我也放到了文末的资源包中。
安装完后如何启用呢?
前置插件安装完了之后,可以在settings界面下找到tag autocomplete,然后选择tag filename下选择zh_zn.csv,最后点击应用设置,重启UI界面就可以用了。
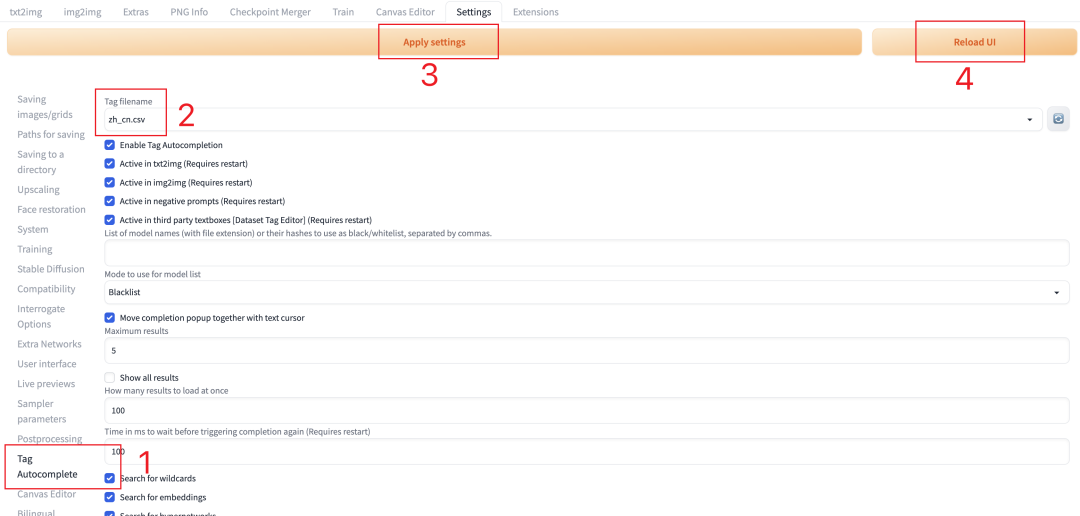
安装完插件后,一定要重启UI才能生效(点开图片可以看大图)
如果你想把整个界面都汉化的话,也可以把我在文末给你的插件包都装上,然后在user interface中一直拉到最后,选择中文。
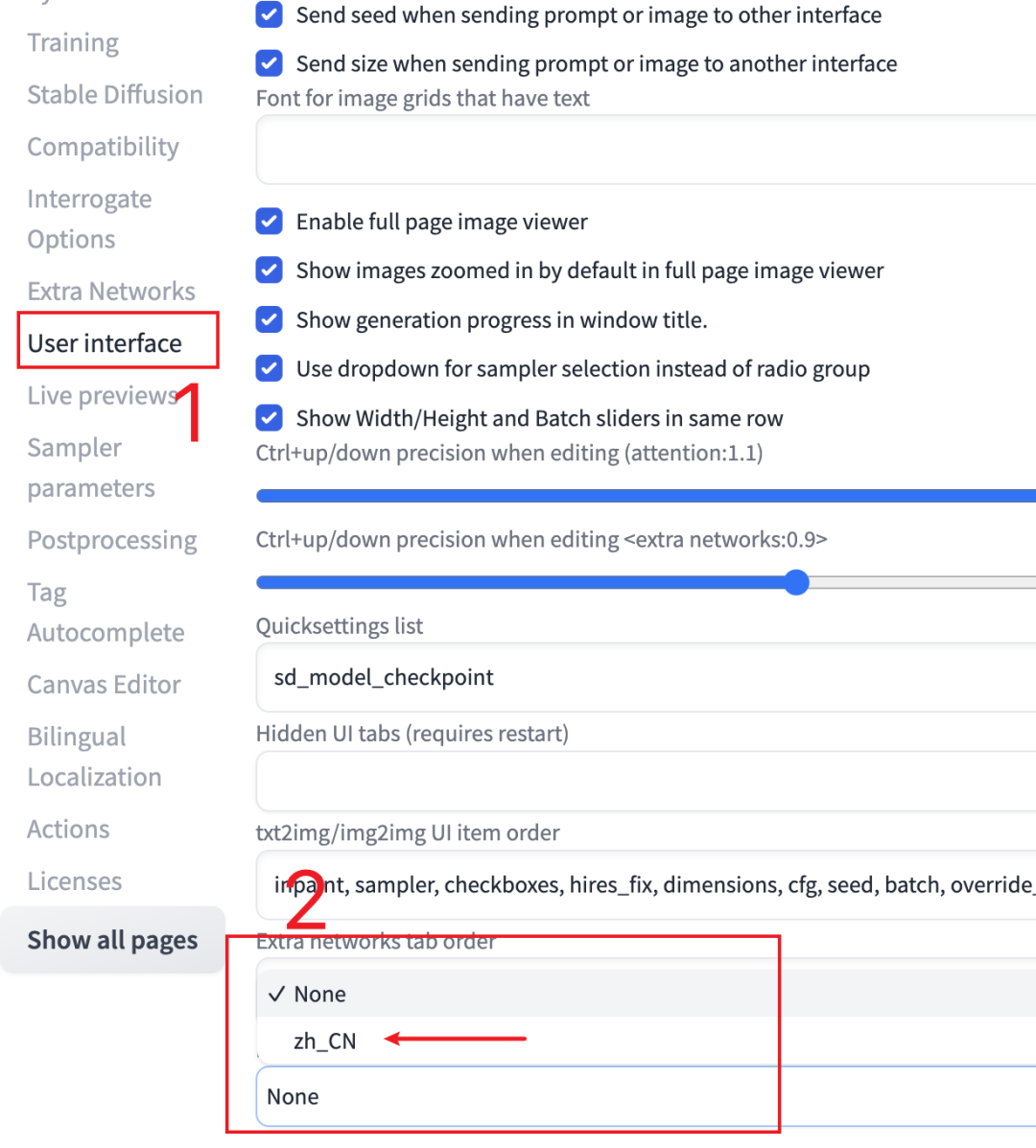
最后应用并重启,就得到了中文界面了。(其实我个人更喜欢英语界面,如果你装完需要返回英文的话,反向操作即可)
中文界面
2)利用Ultimate输出高清图片
https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
Stabel diffusion在生成大尺寸图时容易爆显存,而且生成速度非常慢。这个插件能很好地解决这个问题。
使用方法是在“图生图”里上传一张我们希望高清放大的图片,然后点击脚本选择Ultimate插件
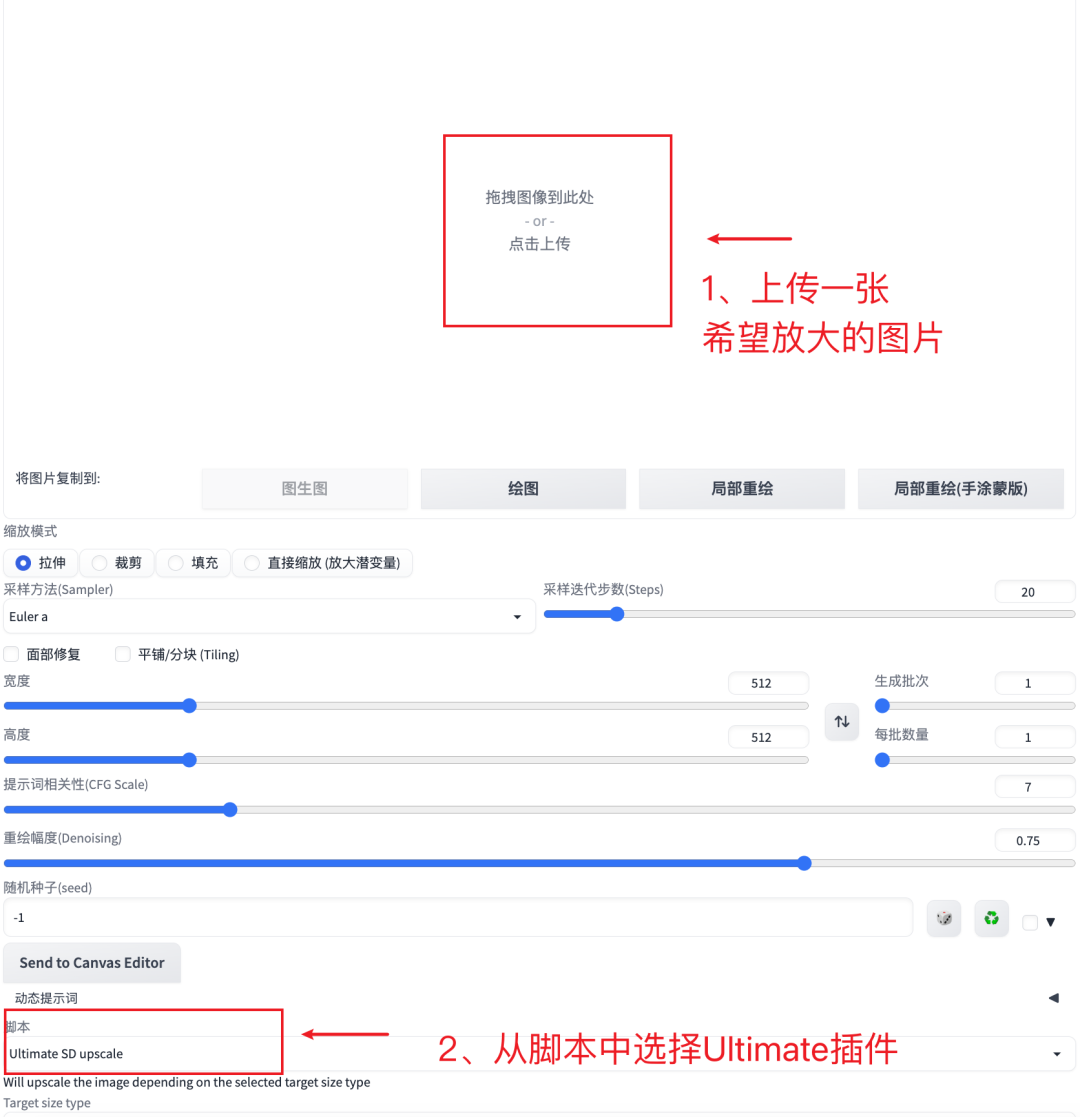
虽然这里参数很多,但其实只需要关注几个参数:
把Target size type改到custom size定义具体尺寸或者改成scale from image size选择放大倍数。把重绘幅度(Denoising)改到0.2,最后点生成。
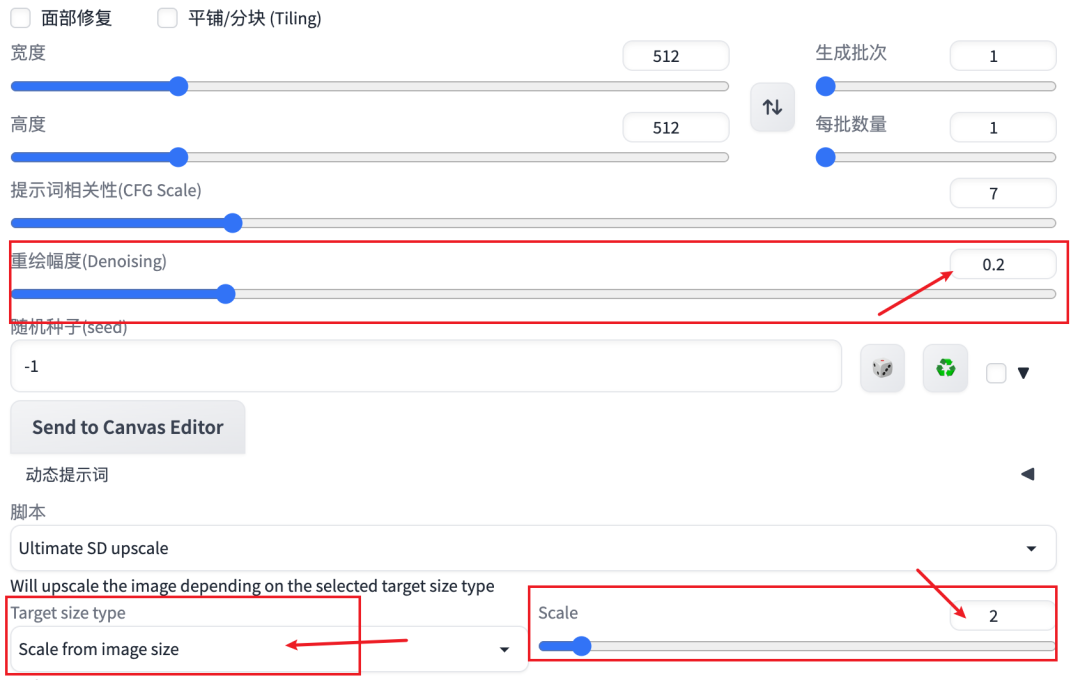
因为是做放大处理,需要的时间可能比较久一些。我放大一张1536×2256的图到3072×4544,花了3分46秒。

左边是放大前的图,右边是放大后的图
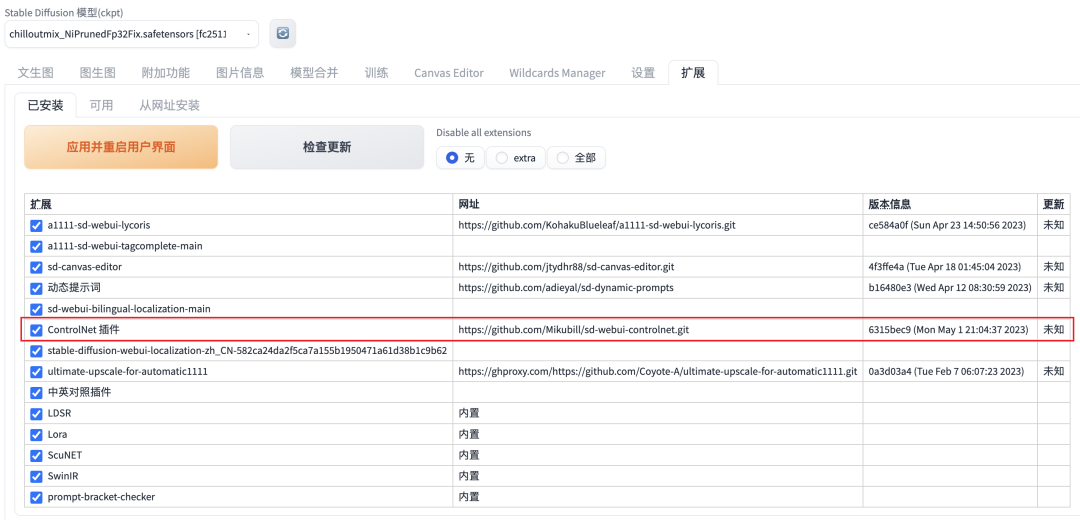
3)ControlNet
这个插件是玩stable diffusion必须装上的插件,功能非常强大,我觉得正是有了这个插件,才让sd变得真正区别于midjourney的地方。我打算单开一篇来讲,因为这个插件可以玩的功能很多,还都非常实用。
插件的官方地址和安装使用说明都在这里,有精力的话强烈建议读一读
https://github.com/Mikubill/sd-webui-controlnet
但如果你看英文文档容易犯困,实操过程中又会发现很多细节讲得不多,会遇上不少卡点疑惑,放心,我后续慢慢写,保持关注吧。
今天这篇文章先简单讲下它的安装,其实安装不算复杂,但有些概念需要理清楚:
先在扩展里选择从网址安装,把这个链接贴进去。
https://github.com/Mikubill/sd-webui-controlnet.git
注意:这里安装的是v1.1版本了,模型效果会更好一些,另外界面UI也有了一些变化,所以文章仔细看咯。
等“安装”按钮下面提示安装好了之后
按提示重启UI界面
重启完成后,你应该能在文生图和图生图里看到这个插件了

如果你不清楚如何设置好它,可以参考我的配置图
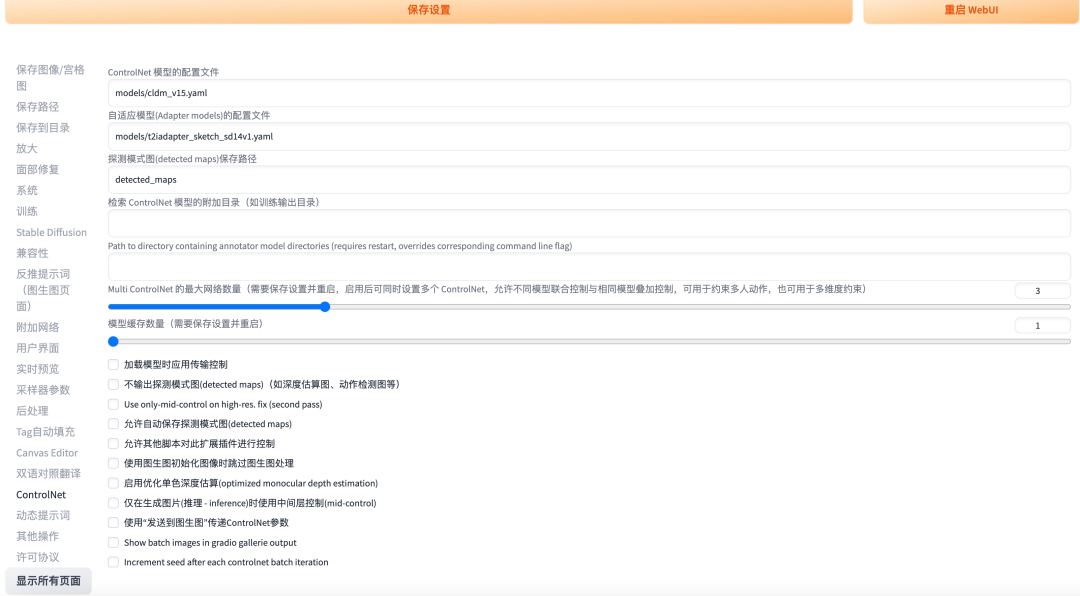
点开可以看大图,设置完成后同样需要重启UI
对于这个插件来说,它还需要装一些模型文件。如果你不安装的话,具体使用的时候它也会自动帮你下载,只是模型都比较大,可能你需要等很久。
模型分为预处理模型和Controlnet所需要的模型(这个模型也有裁剪版本和完整版本),假如你电脑空间大,懒得折腾就直接先下载完整模型,后面再去研究改进的裁剪模型吧。(这些模型资源我都已经打包好在文末的百度云盘里,方便你快速下载)
先安装预处理模型,从这个地址下载预处理模型:
https://huggingface.co/lllyasviel/Annotators/tree/main
然后放到以下目录中
stable-diffusion-webui\extensions\sd-webui-controlnet\annotator
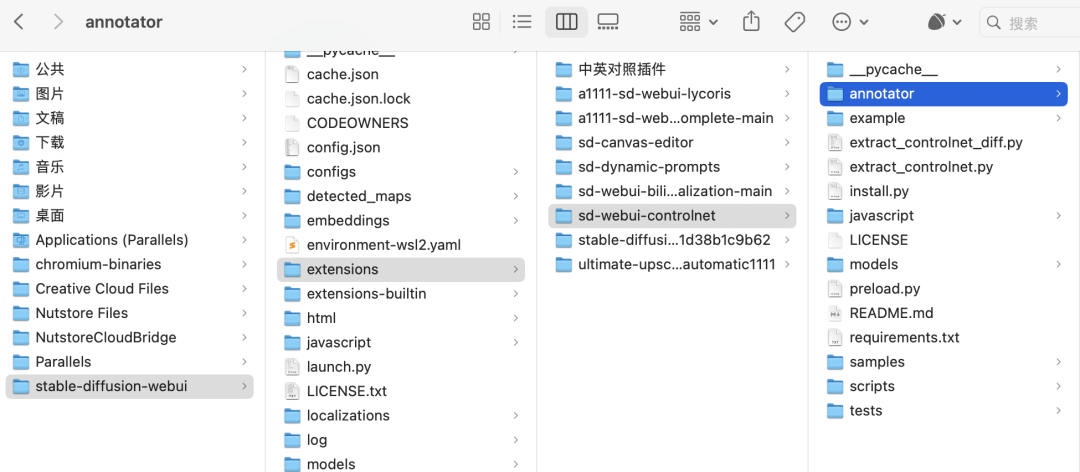
也可以用我后面给到的AI绘画资源包里直接下载,会快一些。
再来安装controlnet所需模型,从这里下载
https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main
然后把它放到以下目录中
stable-diffusion-webui\extensions\sd-webui-controlnet\models

我这里分享的都是最新的v1.1版本,需要提醒的是它与v1.0版本有一个很大的区别,就是界面UI发生了很大的变化,一些操作按钮消失了。
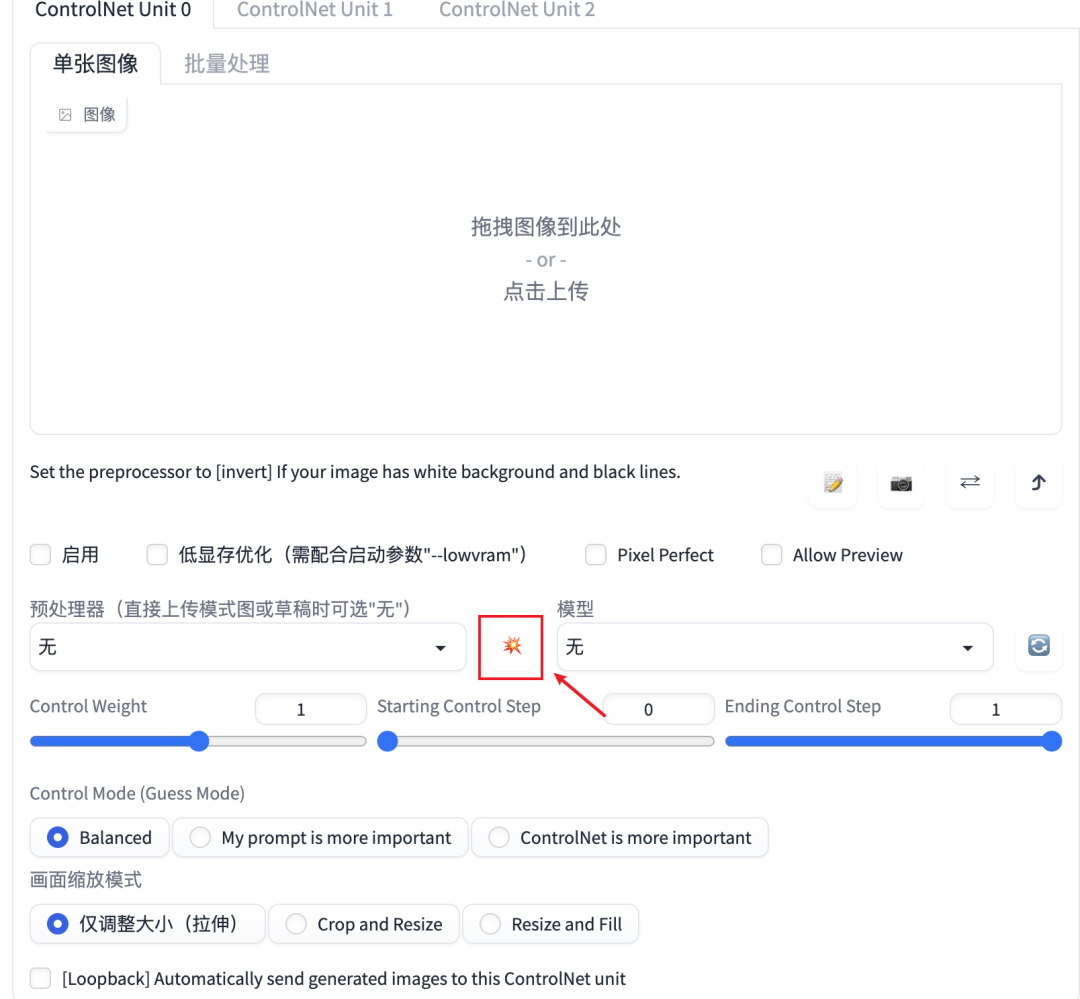
点这个爆炸按钮就能看到预渲染效果
因为UI上的变化,我一度觉得我自己装的不对,后面在官方给的文档中才发现原来是点这个爆炸按钮来操作的。这也说明了在版本迭代时,不应该变动太多,会让用户有一定的学习成本,尤其对于一个初次使用的用户来说,用户体验呀。
安装教程就到这里了,那它到底有哪些用途呢?先用官方图片简单介绍下,下期再详细用案例来讲解。也可以自行先预习下
https://github.com/lllyasviel/ControlNet-v1-1-nightly
我列一些我觉得特别厉害的功能

深度图生成
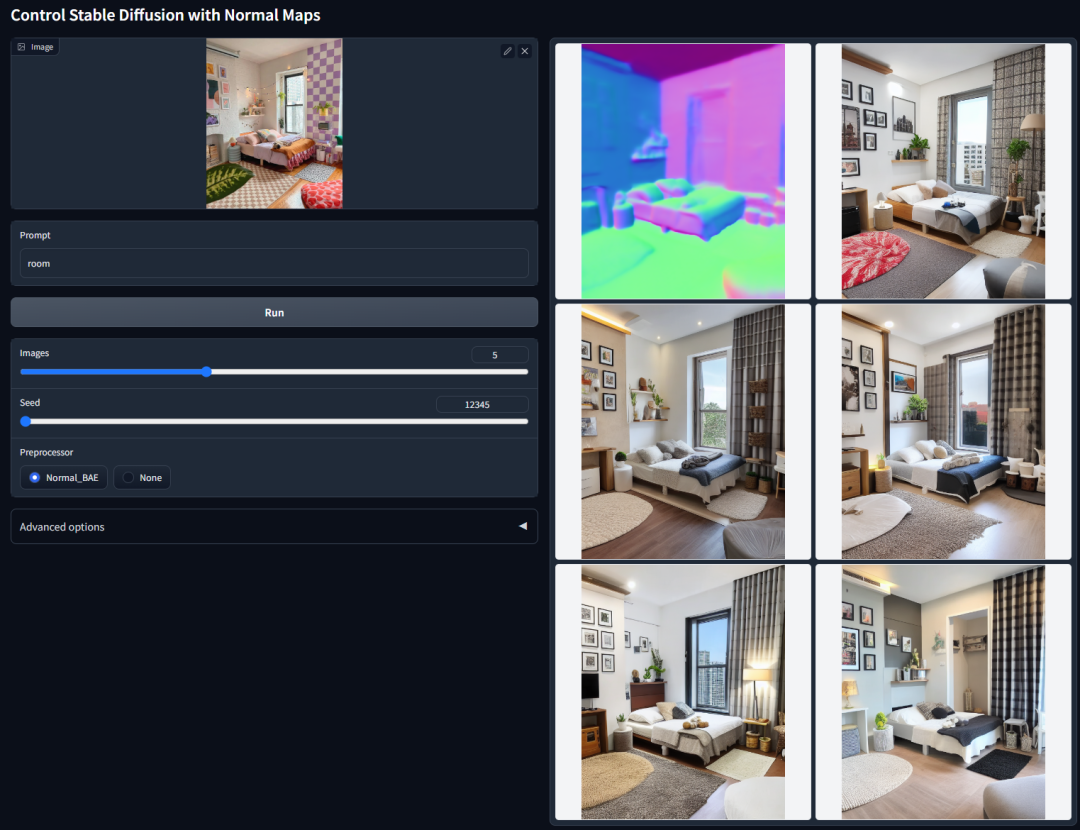
法线图生成
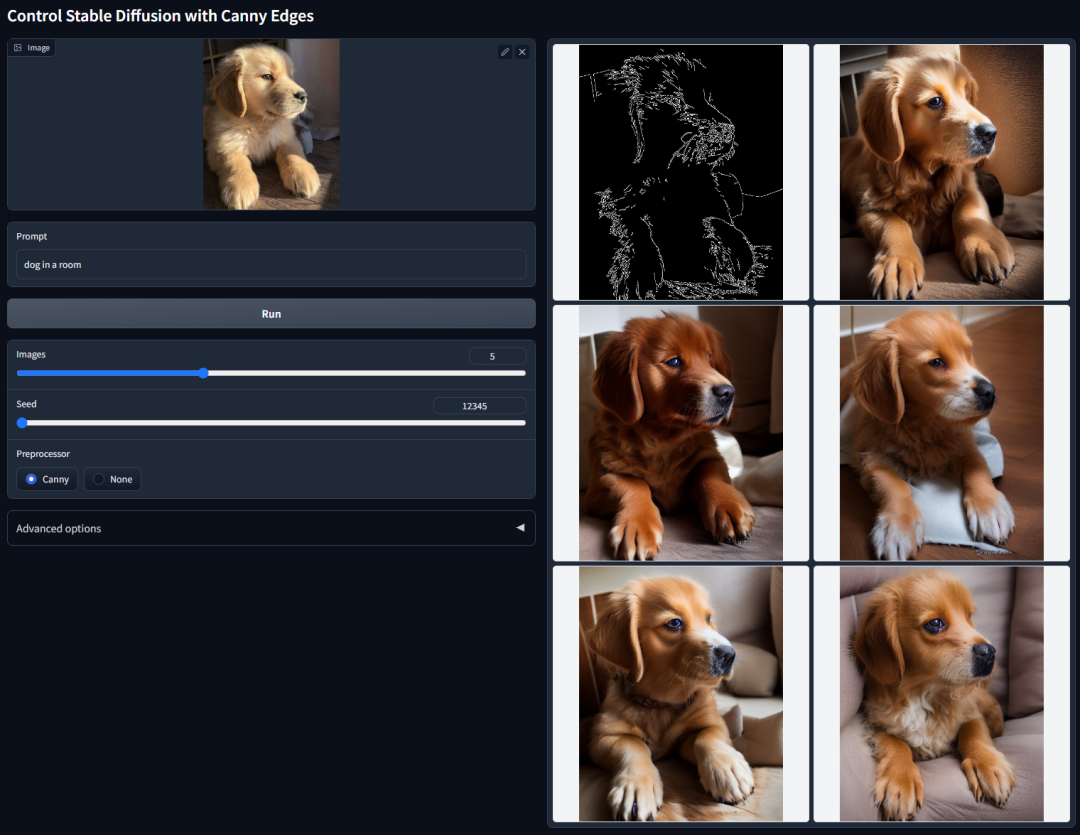
精细描边生成图

直线描边生成图

涂鸦生成
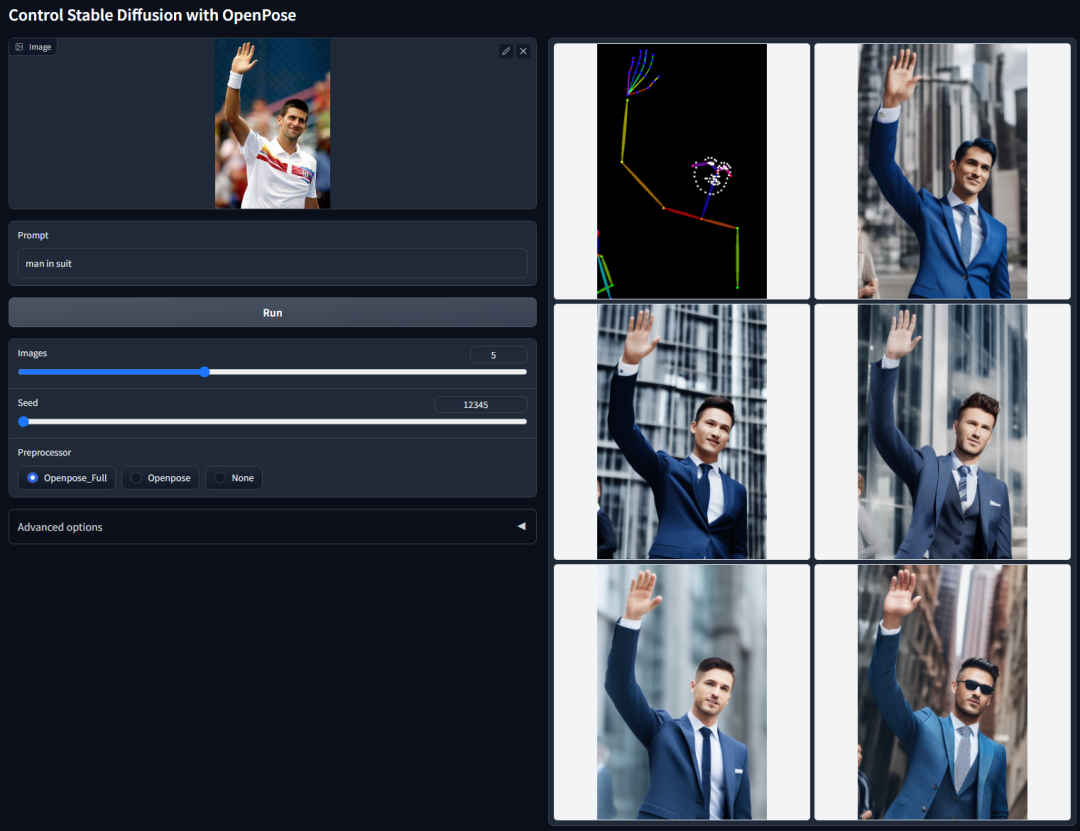
动作pose生成

多人动作Pose

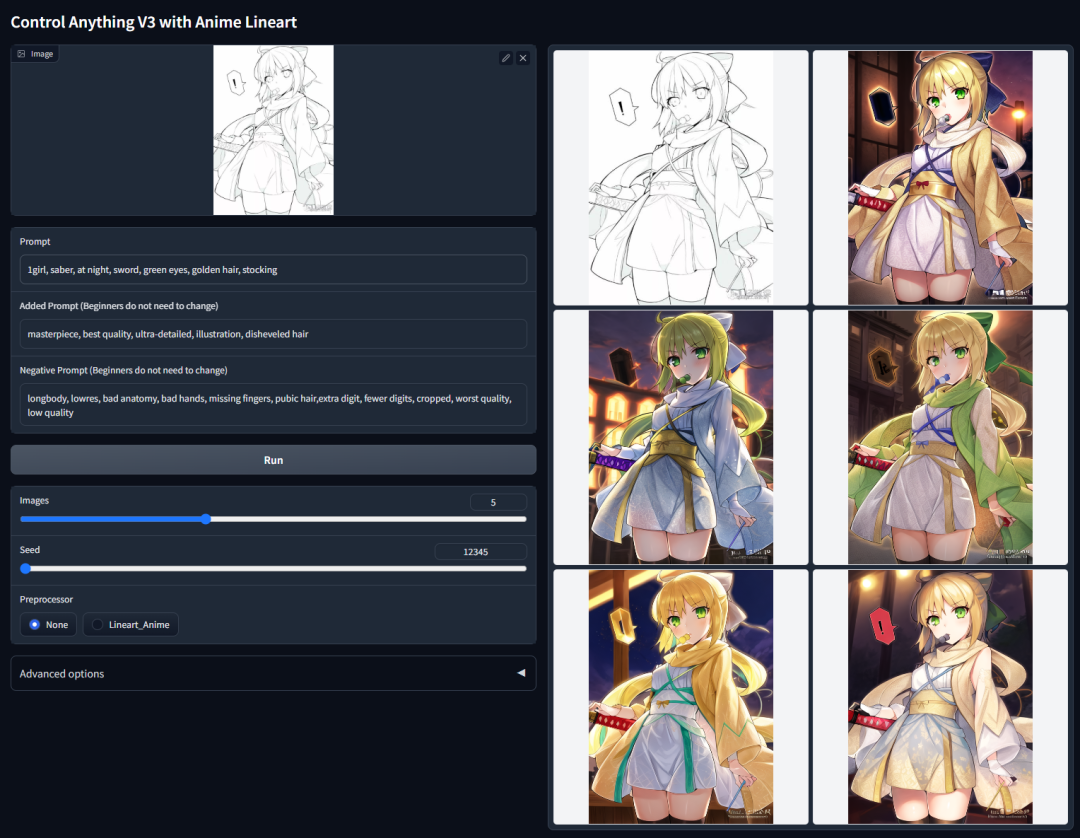
动漫线稿上色
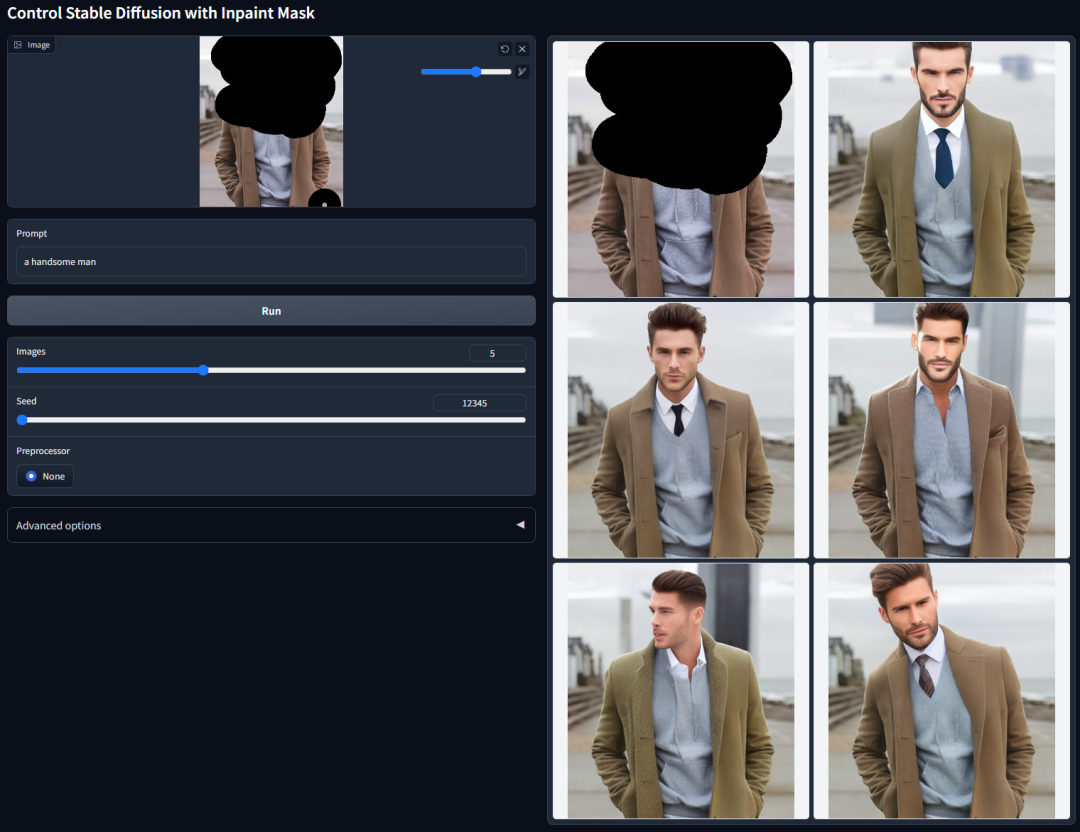
遮罩填充修复(换脸换服装部件,电商换模特非常好用)
在写这个插件的时候,卡了我蛮久,主要是v1.0版本和v1.1版本之间的UI区别比较大,最新版本把确认预览按钮改成了一个爆炸图标,属实难以理解,导致第一次用的时候一直觉得自己安装错了,论UI设计的重要性。
篇幅有限,这篇教程就先写到这里(估计再写长一点估计你的耐心又该吃紧了,我懂你),下期再继续更新吧。
另外,提醒下今天讲的内容一定要实操下,看完不等于学会。实操过程中,你可能会遇到各种坑。但职场经验告诉我:一定要多去挑战复杂的事,遇到 bug在我看来不是坏事,它能让自己“节外生枝”,有机会学到意想不到的知识。
AI资源包,领取方式为:
1)首先在文章底部点个 : 在看 或 分享,再到主页输入框回复: AI资源包

 微信收款码
微信收款码 支付宝收款码
支付宝收款码